Dlaczego kod genetyczny nie jest uniwersalny
W tym poście Matthew – który jest znawcą w tej dziedzinie – odpowiada na pytanie o kod genetyczny, które dostałem od pewnego studenta . Natychmiast przekazałem je Matthew, który napisał obszerną odpowiedź. Pisze on właśnie popularnonaukową książkę o kodzie genetycznym.
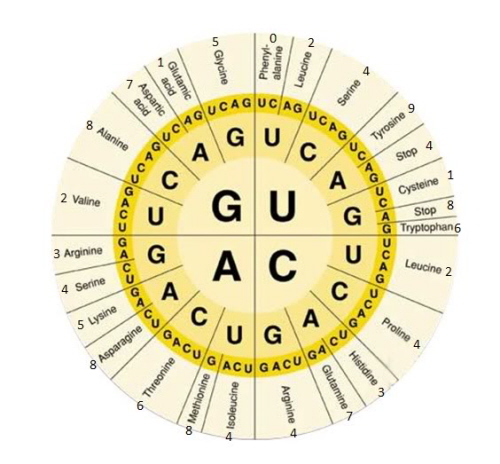
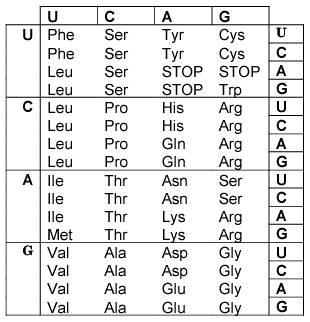
Gdyby były jakieś wątpliwości, co rozumie się przez określenie “kod genetyczny”, to odnosi się ono do tego, jak sekwencja zasad w DNA (są cztery takie zasady) zostaje przetłumaczona na aminokwasy, składniki białek i produkt większości genów. Jak Matthew opisuje poniżej, jest to kod „trójkowy”: każda przylegająca grupa trzech zasad DNA koduje jeden aminokwas. Ponieważ istnieją cztery zasady, istnieją 64 możliwe trójki („kodony”), które w sumie kodują 20 aminokwasów. Znaczy to, że niektóre aminokwasy są kodowane przez więcej niż jedną sekwencję trójkową.
Tutaj jest kod oparty na tłumaczeniu DNA przez RNA (DNA zostaje transkrybowane w RNA zanim następuje translacja w białka). Dla jakiejkolwiek sekwencji trzech zasad zestawiasz najpierw literę z kolumny po lewej, następnie z rzędu na górze i na koniec z kolumny po prawej. Tak więc, na przykład, CAU będzie „His” czyli aminokwas histydyna. „Stop” odnosi się do kodonów STOP: kiedy proces syntezy białka w rybosomach natyka się na ten kodon, translacja zatrzymuje się i łańcuch aminokwasów kończy.
Ten kod jest niemal uniwersalny (post Matthew zajmuje się rzadkimi wyjątkami), co daje nam przekonanie, że współczesne życie pochodzi od jednego przodka. Gdyby było więcej początków życia niż jeden i potomkowie niezależnie rozwinęliby system DNA—>białko, byłoby bardzo nieprawdopodobne, że wszystkie współczesne gatunki miałyby ten sam kod.
Matthew Cobb:
Glendon Wu, doktoryzujący się w immunologii na University of Pennsylvania, zadał pytanie. Był niedawno na wykładzie i dowiedział się, że mitochondria – małe, wytwarzające energię struktury znajdujące się w komórkach wszystkich organizmów wielokomórkowych, a także w niektórych organizmach jednokomórkowych, takich jak drożdże (ta grupa nazywana jest eukariontami) – zawiera inny kod genetyczny niż reszta z nas. Innymi słowy, twoje komórki zawierają dwie różne wersje kodu genetycznego – jedna dla twojego ludzkiego DNA i druga dla DNA w twoich mitochondriach. Zrozumiałe, że zaintrygowało to Glendona i chciał wiedzieć więcej.
Tak się składa, że kończę właśnie książkę popularnonaukową o wyścigu zmierzającym do złamania kodu genetycznego (Life’s Greatest Secret). Chociaż część historyczna kończy się na roku 1967, ostatnie trzy rozdziały doprowadzają opowieść do dnia dzisiejsego, a to obejmuje istnienie alternatywnych kodów genetycznych. To co piszę poniżej to jest zaadaptowana wersja części jednego z tych rozdziałów.
Kod genetyczny zawarty jest w twoim DNA i składa się z 64 trzyliterowych „słów” (znanych jako tryplety albo kodony), z których 61 jest kodami dla 20 aminokwasów potrzebnych twojemu ciału do stworzenia białek, oraz trzech, które mówią „stop”. Jeden kodon koduje zarówno aminokwas, jak również oznacza „start”.
Mamy cztery różne rodzaje liter (A, C, G i T w DNA; kiedy informacja genetyczna ulega ekspresji, przechodzi do RNA, gdzie U zastępuje T), a więc z czterema możliwymi literami na każdej z trzech pozycji w kodonie mamy 4 x 4 x 4 = 64 różne kodony.
W 1967 r. rozszyfrowano ostatnie słowo kodu genetycznego. Był to trzeci kodon STOP – UGA (ze skomplikowanych powodów nazwano go opal). Wszyscy, którzy pracowali z kodem genetycznym, zakładali, że ten kod będzie uniwersalny, to jest, że całe życie na Ziemi będzie używało tego samego sposobu reprezentowania aminokwasów w DNA i RNA. Jak to powiedział w 1961 r. Jacques Monod: „co jest prawdą dla E. coli, jest prawdą dla słonia”.
W listopadzie 1979 r. grupa w Cambridge odkryła, że w ludzkich mitochondriach UGA nie koduje stopu, ale zamiast tego produkuje aminokwas tryptofan. Kod genetyczny nie tylko nie jest uniwersalny, ale ten sam organizm może zawierać dwa różne kody genetyczne, jeden w genomowym DNA i drugi w mitochondriach.
Ten fakt mówi nam coś fundamentalnego o historii życia na naszej planecie. W 1967 r. biolog amerykańska Lynn Margulis zaczęła twierdzić, że mitochondria nie są jedynie mikrostrukturami w naszych komórkach, ale są pozostałością niezależnego organizmu jednokomórkowego, który miliardy lat temu zlał się z przodkiem wszystkich organizmów eukariotycznych, prawdopodobnie jako część stosunku symbiotycznego. Nie ona pierwsza wysunęła tę myśl – na początku XX wieku zarówno Paul Portier, jak Ivan Wallin sugerowali, że mitochondria mogą być symbiontami.
Margulis argumentowała, że te symbiotyczne bakterie zostały następnie zamknięte we wszystkich naszych komórkach i utraciły niezależność, ale nie utraciły własnego, oddzielnego genomu – maleńkiego koła DNA o długości około 15,5 tysiąca zasad (dla porównania, ludzki genom jądrowy zawiera około 3 miliardów zasad). Wygląda na to, że wszystkie mitochondria we wszystkich eukariontach na planecie mają wspólnego przodka, który żył 1,5 miliarda lat temu.
Podobne rzeczy zdarzyły się w roślinach, które w podobny sposób zyskały swoje wytwarzające energię organelle chloroplastu. W obu wypadkach trwają spory o to, jaki właściwie rodzaj mikroba zlał się z czym, a przede wszystkim o szybkość, z jaką to się zdarzyło, ale większość naukowców uważa obecnie, że było to pojedyncze wydarzenie, które umożliwiło temu nowemu organizmowi hybrydowemu na rośnięcie do większych rozmiarów i zdobycie energii wymaganej przez bardziej złożone organizmy.
Niezmiernie małe rozmiary genomu mitochondrialnego i jego osobliwe użycie kodonów można wyjaśnić historią tego symbiotycznego stosunku. Genom mitochondrialny koduje bardzo mało białek – albo stracił większość innych genów przed lub krótko po fuzji z naszymi przodkami, albo zostały one włączone w genomowy DNA gospodarza – a więc pojawienie się nowych kodonów w DNA mitochondrialnym poprzez mutację nie miałoby istotnego wpływu na symbionta, którego większość potrzeb zaspokajała komórka gospodarza.
Nie tylko mitochondria mają niezwykły kod genetyczny. W wielu odkryciach, poczynając od 1985 r. stwierdzono, że jednokomórkowe orzęski – maleńkie organizmy takie jak Paramecium – wykazują odmiany jądrowego kodu genetycznego, które pojawiły się kilkakrotnie podczas ewolucji. U niektórych gatunków orzęsków UAA i UAG kodują kwas glutaminowy zamiast stop, podczas gdy u innych UGA koduje tryptofan.
W kilku rzadkich wypadkach w organizmach jednokomórkowych bez jądra UGA i UAG zostały nawet przekodowane przez dobór naturalny do kodowania dodatkowych aminokwasów, nie znajdowanych normalnie w żywych organizmach – selenocysteiny i pirolizyny. Niedawne badanie 5,6 trylionów par zasad DNA z ponad 1700 próbek bakterii i bakteriofagów wyizolowanych ze środowiska naturalnego, włącznie z ciałem ludzkim, ujawniło, że w znaczącym odsetku sekwencji kodony STOP dostały zadanie kodowania aminokwasów, zaś badanie dotychczas niezbadanych mikrobów ujawniło, że w jednej grupie zadanie UAG zmieniło się ze stop do kodowania glicyny.
Wiadomo, że istnieje ponad 15 alternatywnych, niekanonicznych kodów genetycznych i można założyć, że jeszcze więcej pozostaje do odkrycia. W kodach niekanonicznych niemal zawsze inne zadani wyznaczone jest kodonom STOP; może to wskazywać, że jest coś w maszynerii kodonów STOP, co czyni je szczególnie podatnymi na zmianę, lub też może być po prostu tak, że jak długo organizm może nadal kodować stop przy użyciu drugiego kodonu, przeznaczenie jednego z kodonów STOP na aminokwas nie powoduje żadnych problemów.
Dokładny proces, w jaki zachodzi zmiana w kodonie, był przedmiotem bardzo wielu badań teoretycznych i eksperymentalnych i przedstawiono szereg hipotez, by wyjaśnić, jak mogą powstawać odmiany kodu.
Obecny faworyt nazywa się modelem przechwycenia kodonu i został przedstawiony po raz pierwszy przez Jukesa i Osawę w 1987 r. Według tego modelu losowe efekty, takie jak dryf genetyczny, mogą prowadzić do zniknięcia danego kodonu w danym genomie; byłby to efekt podobny do tego, który prowadzi do przechwycenia kodonu przez tRNA, który koduje innym aminokwas.
Niedawne badanie eksperymentalne genetycznie zmodyfikowanych bakterii, w których sztucznie zastąpiono niektóre kodony, poparły ten model, a nawet sugerowały, że zmiana roli kodonów może być w pewnych warunkach korzystna, dostarczając organizmowi szerszego zakresu funkcji.
Reakcje naukowców na nieuniwersalność kodu genetycznego ujawnia coś ważnego o naturze biologii. Było to zupełnie nieoczekiwane i sprzeczne z wszystkimi założeniami wszystkich badaczy, którzy studiowali kod genetyczny, pokazując, że Monod mylił się – co jest prawdziwe dla E. coli, niekoniecznie jest prawdziwe dla słonia. Mimo jednak tej rewolucji podstawowe stanowisko, ustalone podczas łamania kodu, pozostało nienaruszone.
Ścisła uniwersalność kodu nie była prawem ani nawet wymogiem. Jedynym wymogiem było, że każde odejście od tego założenia da się wyjaśnić w ramach ewolucji i przez dające się przetestować hipotezy o historii organizmów. To zostało z powodzeniem spełnione.
Chociaż kod genetyczny nie jest ściśle uniwersalny, jest bezsporne, że życie powstało tylko raz i że wszyscy pochodzimy od populacji komórek, które żyły ponad 3,5 miliarda lat temu, znanych jako Ostatni Uniwersalny Wspólny Przodek (Last Universal Common Ancestor) czyli LUCA. Alternatywne kody są cechami wtórnymi – pojawiły się po ewolucji całego obecnego życia.
Fakt, że wszystkie organizmy używają aminokwasów lewoskrętnych i uniwersalność RNA jako sposobu zestawiania aminokwasów i tworzenia białek, są bardzo silnym argumentem na poparcie tej hipotezy. W 2010 r. Douglas Theobold wyliczył, że hipoteza, iż wszelkie życie jest spokrewnione, “jest 102860 razy bardziej prawdopodobna niż najbliższa hipoteza konkurencyjna”.
Odkrytą różnorodność w kodzie można wyjaśnić albo w kategoriach głębokiej historii ewolucyjnej eukariontów – ujawniając w ten sposób fascynujący fakt, że nasza ewolucja zależała do przypadkowego zlania się dwóch komórek – albo czymś niedawnym i lokalnym w historii życia konkretnej grupy organizmów, co prawdopodobnie zdarzyło się w wypadku orzęsków.
Mam nadzieje, że odpowiada to na twoje pytanie, Glendon!
Why the genetic code is not universal
Why Evolution Is True, 28 września 2014
Tłumaczenie: Małgorzata Koraszewska

Matthew Cobb
Biolog i pisarz, mieszka i pracuje w Manchesterze, niedawno w Stanach Zjednoczonych ukazała się jego książka „Generation”, a w Wielkiej Brytanii „The Egg & Sperm Race”. Systematycznie publikuje w "LA Times", "Times Literary Supplement", oraz "Journal of Experimental Biology".